WhereRustcSpendsItsTime
So a couple weeks ago I was a little stung by the quote from This Week In Rust: “Rust compilation is so slow that I can fix the bugs while it still compiles the crates”. On the one hand, I have unfond memories of waiting for a Typescript project to compile, pack (aka link), minify (aka optimize), and so on, over and over, on every change. At least if it had been Rust I’d have been able to fix the bugs while it was doing this. On the other hand, it’s also mostly true: compiling Rust is heckin’ slow. So I’ve decided to dust off a backburner project for a while, and figure out just where rustc spends most of its time.
There’s one key thing that made me curious about all this in the first place… Once upon a time I read an ancient, lost reddit post where an unknown compiler dev mentioned that rustc was fairly stupid in how it generated its output, and created a whole lot of unnecessary IR code that it then just shoved into LLVM to clean up. This caught my attention enough to stick in my mind for years, at least in concept. I have no idea if this is still true (I vaguely remember that it was talked about shortly after 1.0), to what extent it was true (I recall the figure of 100’s of megabytes of IR generated for even fairly simple things), or if this was ever true (I might have imagined the whole thing). But the time has come for me to find out.
Assumptions
First off, what do I actually know about rustc? Not a whole heck of a lot, but I know a few things about compilers in general. Compilers are one of the most fun and most fundamental types of programs because they’re essentially a gigantic pure function: inputs go in (source code) and outputs come out (machine code). In between there’s not a lot of user interaction, network stuff, I/O, or anything like that, just computation. Compilers are traditionally structured as a linear pipeline of transformations that occur in distinct steps. The traditional compiler pipeline is: lex text to tokens -> parse tokens to a syntax tree -> transform syntax tree to intermediate representation (IR) -> transform IR to more/different IR, optimizing it along the way -> transform final IR into machine code. This is not always 100% accurate, since these phases can overlap more than a little, but it is always a good place to start. I know that currently in rustc, there’s several stages of IR: HIR (high-level intermediate representation), MIR (mid-level intermediate representation), and then LLVM IR. I would expect there to be a LIR someday, but I don’t know if it exists yet. I don’t yet know exactly what gets represented where, or how, but I think MIR contains enough information to do borrow-checking, and I’ve at least dinked around a little with LLVM so I have some clue of what it looks like.
I do know that there are some TOP MEN working on optimizing rustc from the micro-optimization and benchmark level, so I don’t need to look too deeply into the specifics of data structures and stuff. I can just assume that if someone hasn’t looked at the details of some part of the compilation process, its on a to-do list somewhere. That suits me fine, since I’m more interested in the holistic view (“steps X and Y take up most of the time because of A and B”) than the specific view (“a lot of time is spent accessing this particular hashtable in this one place”). I’m also not actually going to try to do any optimizatio myself, just try to figure out where time gets spent.
And, of course, I think I know that most of rustc’s time is spent in code optimization.
Watching the compiler do stuff
I’m going to be using two key test programs: oorandom which is not quite trivial but is very small and simple, and nalgebra which is big and complicated and uses an enormous amount of interesting and hairy metaprogramming stuff to lean hard on Rust’s optimization. We are using oorandom 11.1.0 and nalgebra 0.18.1, and rustc 1.40.0-nightly 20cc75272 2019-10-09.
Okay, so first off, building oorandom in debug mode
takes about 0.25 seconds, and building nalgebra takes about
25 seconds. Hopefully that makes a sufficiently interesting spread of
samples! Considering nalgebra is about 100x larger in terms of
significant lines of code, it’s semi-sane that it takes 100x more time.
Compiling them in release mode takes 0.2 seconds and 22 seconds,
respectively. Now that’s interesting since I’d expect a debug compile to
be faster than release, and usually it is. However, it’s not interesting
enough to dig into it further to see if it’s more than experimental
error; we’re just going to compile in release mode all the time, since
the cost of optimization is something I want to look at. Second off,
nalgebra has some dependencies it needs to build as well, but it looks
like rustc’s built-in profiling stuff only measures the crate you’re
actually building, not its dependencies, which is what we want.
Excellent.
Third off, we can get a high-level overview of where rustc spends its
time with the following invocation:
cargo +nightly rustc -- -Z time-passes. This is basically
the information I want to start with, so huzzah! For oorandom, it
produces this giant whack of output:
time: 0.001; rss: 64MB parsing
time: 0.000; rss: 64MB attributes injection
time: 0.000; rss: 64MB recursion limit
time: 0.000; rss: 64MB plugin loading
time: 0.000; rss: 64MB plugin registration
time: 0.000; rss: 64MB pre-AST-expansion lint checks
time: 0.000; rss: 64MB crate injection
time: 0.007; rss: 74MB expand crate
time: 0.000; rss: 74MB check unused macros
time: 0.007; rss: 74MB expansion
time: 0.000; rss: 74MB maybe building test harness
time: 0.000; rss: 74MB AST validation
time: 0.000; rss: 74MB maybe creating a macro crate
time: 0.001; rss: 77MB name resolution
time: 0.000; rss: 77MB complete gated feature checking
time: 0.000; rss: 77MB lowering AST -> HIR
time: 0.000; rss: 77MB early lint checks
time: 0.000; rss: 79MB validate HIR map
time: 0.001; rss: 79MB indexing HIR
time: 0.000; rss: 79MB load query result cache
time: 0.000; rss: 79MB dep graph tcx init
time: 0.000; rss: 79MB looking for entry point
time: 0.000; rss: 79MB looking for plugin registrar
time: 0.000; rss: 79MB looking for derive registrar
time: 0.000; rss: 79MB misc checking 1
time: 0.001; rss: 82MB type collecting
time: 0.000; rss: 82MB impl wf inference
time: 0.000; rss: 92MB unsafety checking
time: 0.000; rss: 92MB orphan checking
time: 0.007; rss: 92MB coherence checking
time: 0.001; rss: 92MB wf checking
time: 0.003; rss: 94MB item-types checking
time: 0.012; rss: 96MB item-bodies checking
time: 0.000; rss: 96MB match checking
time: 0.000; rss: 96MB liveness checking + intrinsic checking
time: 0.001; rss: 96MB misc checking 2
time: 0.007; rss: 102MB MIR borrow checking
time: 0.000; rss: 102MB dumping Chalk-like clauses
time: 0.000; rss: 102MB MIR effect checking
time: 0.000; rss: 102MB layout testing
time: 0.000; rss: 102MB privacy access levels
time: 0.000; rss: 102MB private in public
time: 0.000; rss: 102MB death checking
time: 0.000; rss: 102MB unused lib feature checking
time: 0.005; rss: 109MB crate lints
time: 0.000; rss: 109MB module lints
time: 0.005; rss: 109MB lint checking
time: 0.000; rss: 109MB privacy checking modules
time: 0.006; rss: 109MB misc checking 3
time: 0.001; rss: 113MB metadata encoding and writing
time: 0.000; rss: 113MB collecting roots
time: 0.003; rss: 113MB collecting mono items
time: 0.003; rss: 113MB monomorphization collection
time: 0.000; rss: 113MB codegen unit partitioning
time: 0.003; rss: 128MB codegen to LLVM IR
time: 0.000; rss: 130MB assert dep graph
time: 0.000; rss: 130MB serialize dep graph
time: 0.008; rss: 130MB codegen
time: 0.001; rss: 136MB llvm function passes [oorandom.d5irq2oa-cgu.0]
time: 0.003; rss: 136MB llvm function passes [oorandom.d5irq2oa-cgu.1]
time: 0.004; rss: 136MB llvm module passes [oorandom.d5irq2oa-cgu.0]
time: 0.016; rss: 135MB llvm module passes [oorandom.d5irq2oa-cgu.1]
time: 0.003; rss: 135MB LTO passes
time: 0.005; rss: 135MB codegen passes [oorandom.d5irq2oa-cgu.0]
time: 0.016; rss: 139MB LTO passes
time: 0.012; rss: 139MB codegen passes [oorandom.d5irq2oa-cgu.1]
time: 0.055; rss: 140MB LLVM passes
time: 0.000; rss: 140MB serialize work products
time: 0.001; rss: 140MB linking
time: 0.134; rss: 119MB total
Finished release [optimized] target(s) in 0.25sWhew, that’s a lot of stuff! I’m counting 69 steps total, about half
of which are listed at the top level. It also isn’t fully precise, since
Cargo takes 0.25 seconds and the compiler’s total is 0.134 seconds, but
if you add all the values there it adds up to 0.199 seconds and if you
add all the toplevel values it’s 0.113 seconds. So, there’s some
measurement error to be aware of; these are quick and dirty values.
Regardless, for oorandom there’s basically four things that
take time: “LLVM passes”, “item-bodies checking”, “codegen” and
“expansion”.
Let’s look at nalgebra:
time: 0.092; rss: 88MB parsing
time: 0.000; rss: 88MB attributes injection
time: 0.000; rss: 88MB recursion limit
time: 0.000; rss: 88MB plugin loading
time: 0.000; rss: 88MB plugin registration
time: 0.007; rss: 89MB pre-AST-expansion lint checks
time: 0.000; rss: 89MB crate injection
time: 0.245; rss: 159MB expand crate
time: 0.000; rss: 159MB check unused macros
time: 0.245; rss: 159MB expansion
time: 0.000; rss: 159MB maybe building test harness
time: 0.010; rss: 159MB AST validation
time: 0.000; rss: 159MB maybe creating a macro crate
time: 0.186; rss: 184MB name resolution
time: 0.022; rss: 184MB complete gated feature checking
time: 0.125; rss: 225MB lowering AST -> HIR
time: 0.023; rss: 225MB early lint checks
time: 0.024; rss: 234MB validate HIR map
time: 0.127; rss: 234MB indexing HIR
time: 0.000; rss: 234MB load query result cache
time: 0.000; rss: 234MB dep graph tcx init
time: 0.000; rss: 234MB looking for entry point
time: 0.000; rss: 234MB looking for plugin registrar
time: 0.000; rss: 234MB looking for derive registrar
time: 0.056; rss: 248MB misc checking 1
time: 0.104; rss: 255MB type collecting
time: 0.009; rss: 257MB impl wf inference
time: 0.001; rss: 273MB unsafety checking
time: 0.002; rss: 273MB orphan checking
time: 1.639; rss: 273MB coherence checking
time: 3.593; rss: 295MB wf checking
time: 0.357; rss: 293MB item-types checking
time: 7.038; rss: 309MB item-bodies checking
time: 0.270; rss: 317MB match checking
time: 0.042; rss: 317MB liveness checking + intrinsic checking
time: 0.312; rss: 317MB misc checking 2
time: 6.173; rss: 382MB MIR borrow checking
time: 0.000; rss: 382MB dumping Chalk-like clauses
time: 0.003; rss: 382MB MIR effect checking
time: 0.000; rss: 382MB layout testing
time: 0.067; rss: 384MB privacy access levels
time: 0.033; rss: 384MB private in public
time: 0.035; rss: 386MB death checking
time: 0.007; rss: 386MB unused lib feature checking
time: 0.038; rss: 386MB crate lints
time: 0.049; rss: 389MB module lints
time: 0.088; rss: 389MB lint checking
time: 0.108; rss: 389MB privacy checking modules
time: 0.338; rss: 389MB misc checking 3
time: 1.080; rss: 417MB metadata encoding and writing
time: 0.003; rss: 417MB collecting roots
time: 0.006; rss: 417MB collecting mono items
time: 0.009; rss: 417MB monomorphization collection
time: 0.000; rss: 417MB codegen unit partitioning
time: 0.013; rss: 448MB codegen to LLVM IR
time: 0.000; rss: 448MB assert dep graph
time: 0.000; rss: 448MB serialize dep graph
time: 0.026; rss: 448MB codegen
time: 0.001; rss: 448MB llvm function passes [nalgebra.6tz72kds-cgu.2]
time: 0.003; rss: 455MB llvm function passes [nalgebra.6tz72kds-cgu.1]
time: 0.003; rss: 455MB llvm module passes [nalgebra.6tz72kds-cgu.2]
time: 0.001; rss: 455MB llvm function passes [nalgebra.6tz72kds-cgu.0]
time: 0.001; rss: 454MB llvm module passes [nalgebra.6tz72kds-cgu.0]
time: 0.029; rss: 452MB llvm module passes [nalgebra.6tz72kds-cgu.1]
time: 0.002; rss: 451MB LTO passes
time: 0.002; rss: 451MB LTO passes
time: 0.003; rss: 451MB codegen passes [nalgebra.6tz72kds-cgu.0]
time: 0.005; rss: 453MB codegen passes [nalgebra.6tz72kds-cgu.2]
time: 0.042; rss: 455MB LTO passes
time: 0.056; rss: 456MB codegen passes [nalgebra.6tz72kds-cgu.1]
time: 0.149; rss: 456MB LLVM passes
time: 0.000; rss: 456MB serialize work products
time: 0.010; rss: 459MB linking
time: 21.782; rss: 423MB total…now that’s interesting. Even building in release mode, codegen and LLVM don’t seem to take much time, 0.2 seconds of the total. Instead 19 of the 22 seconds are spent here:
time: 1.639; rss: 273MB coherence checking
time: 3.593; rss: 295MB wf checking
time: 0.357; rss: 293MB item-types checking
time: 7.038; rss: 309MB item-bodies checking
time: 0.312; rss: 317MB misc checking 2
time: 6.173; rss: 382MB MIR borrow checkingThis is NOT what rustc spending most of its time in codegen looks
like! And ALSO not what oorandom’s results look like! That
was so contrary to expectations that I tried again with an older version
of the nightly compiler I had lying around, to see if something weird
had regressed recently. It gave the same results. So then I tried
building a different project entirely that I knew took a while to build,
ggez 0.5.1. ggez doesn’t really do much fancy
metaprogramming stuff, but does use a lot of other libraries,
so apparently finalizing and linking each of those got counted
individually so time-passes spit out 1000+ lines of various
“llvm passes” and “codegen passes”. The things that took a long time in
nalgebra, “item-bodies checking” and “MIR borrow checking”, still were
significant minorities in ggez that together took nearly a
second, but the vast majority of time was spent in codegen and LLVM, at
6+ seconds each.
Desperate to find some sort of consistent pattern, I tried to build a
simple hello-world program using the rendy graphics library
(release 0.4), which like ggez has a large number of fairly
straightforward dependencies but like nalgebra also does a
big honkin’ pile of generic specialization as well. That took 15 seconds
to build, 9 of which was spent in “codegen”. Neither this nor
ggez spent anywhere near as much time in
typechecking and borrow-checking as nalgebra did.
And when I built an actual binary with rendy it also
spent several seconds in the “linking” stage, which hasn’t been a
significant contributor at all when just building libraries, even
libraries like ggez that one would expect to be linked with a bunch of
other libraries.
…So with five different projects we get five different sorts of results. The plot thickens.
Take a deep breath…
Okay, rustc’s -Z codegen-passes is a decent place to
start but the more you look at it the more obvious it becomes that it’s
just an approximation that doesn’t stand up to close scrutiny too well.
If we’ve learned anything by now it’s that this is complicated.
So:
- Validation and borrow-checking is usually a significant minority of
the time consumed, but only a majority in weird codebases like
nalgebra. - Codegen and LLVM takes a lot of time sometimes but not others
- Linking binaries takes a lot of extra time but linking libraries not so much
What is also important is what we don’t really see much of:
- Parsing is negligible. All the books on compiler writing that say parsing is a performance bottleneck are out of date. While Rust is relatively easy to parse and I’m sure a C++ compiler spends a lot more work on it, parsing is not a performance problem for a well-designed language with modern hardware and algorithms.
- Macro expansion is always in the list enough to tip the scales, but
is always overwhelmed other things. If we were looking at
structoptorserdeor something else very macro-heavy that might change though. (Heck, why don’t we check? Nope,serde’s numbers look a lot likenalgebra’s, and something usingstructoptdoesn’t spend significantly more time in macro expansion than anything else. Might be that you need to actually use the macros quite a lot for the cost of the macros to add up, and just defining even complex ones doesn’t do much.) - There doesn’t seem to be much time spent in doing things like building IR’s and transforming them compared to everything else. As far as I can tell at this point, going from HIR to MIR and from MIR to LLVM IR takes trivial amounts of time. Either doing this is cheap/well-optimized, or rustc just doesn’t do a lot of it.
We need information. Information! Before we go too much
deeper though, let’s look at memory. The original assertion that got me
interested in this was about how much data was produced in each step of
compilation, after all. And since rustc’s time-passes
conveniently spits out RSS numbers along with its timings (resident set
size, basically how much memory the OS thinks the program is using), we
might as well use them. RSS is not a great way to measure
memory usage, but we can start there. So, graphs!
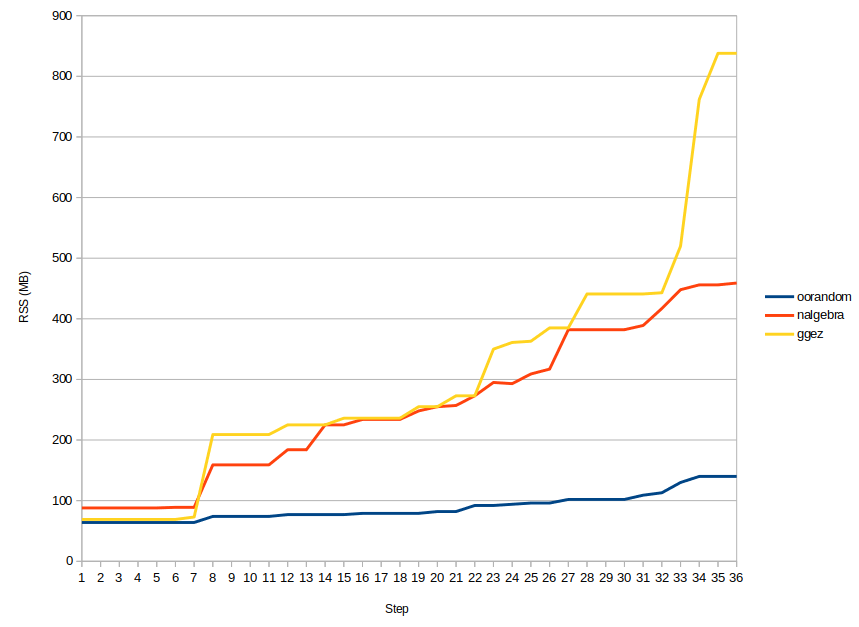
First off: rustc is a little bit of a hog, taking 50+ megabytes just
doing nothing. Most of this is probably just the actual code of the
executable; most of the code seems to be in a DLL,
librustc_driver.so, which is 60 MB. Though there’s also an
LLVM DLL along with it that’s 80 megs, so. There’s a lot of
code here.
Second, there’s a continual upward trend of memory usage through the program’s execution, which isn’t necessarily surprising, but there seems to be a couple more notable jumps. Let’s look at a normalized version of the graph, where the memory usage is scaled by the max memory used during that run:
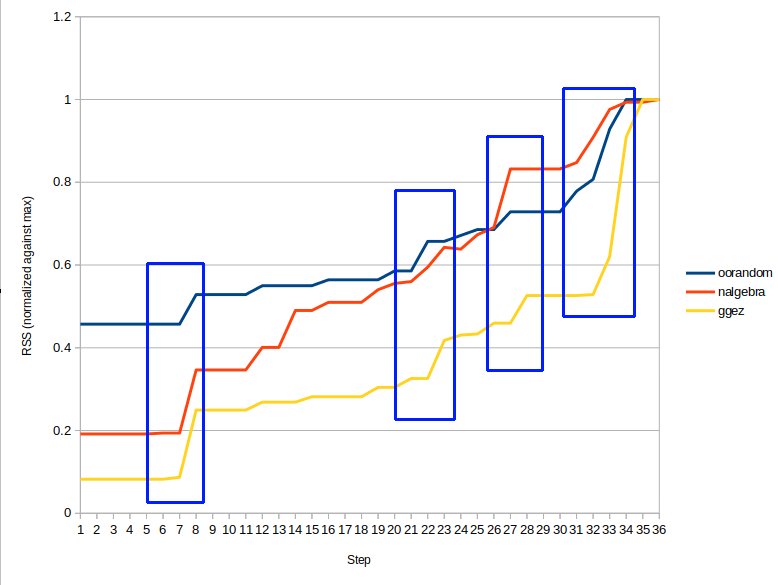
Aha, yes. Four distinct jumps, each more or less present in all
programs, but different magnitudes in each. I’ve outlined ’em in the
graph. The graph isn’t quite exact ’cause making it involved some
copy-pasting by hand, and as mentioned, -Z codegen-passes
isn’t the most reliable tool, but it gives us something to look for. The
compiler stages associated to each jump seem to be (roughly)
“expansion”, “coherence checking”, “MIR borrow checking”, and of course
“codegen”+“LLVM passes”. Not much more to say without going deeper, just
that some of the time-intensive passes are also quite
memory-intensive.
…before the plunge.
I love the Rust community’s documentation habits. Keep leading from the front, compiler team.
It appears that -Z codegen-passes is basically now made
obsolute by a more precise (and hopefully more accurate)
self-benchmarking method, a -Z self-profile flag with a set
of tools appropriately called measureme.
This outputs some binary profiling data that then gets crunched and
displayed by one of measureme’s tools,
summarize. Or even better, it can output ♥flame
graphs♥.



(Right click on an image and select “view image” and you will be able to zoom in on various bits in the SVG.)
So we have an interesting spread. In oorandom, we get
about 35% static analysis, somewhere in the range of 20-25% optimization
and codegen, and the rest is dross – including 30% or so of time not
accounted for, but since that’s only 0.05 seconds or so I’m not too
worried. nalgebra spends over 90% of its measured time on
static analysis, most of which is “mir_borrowck” and “type-check crate”,
which again fits more or less what we saw from our previous attempt. And
ggez, which I’m including anyway now since since it’s
apparently a different enough workload to be interesting, spends 23% of
its time in static analysis, a whopping 30ish% of the time unaccounted
for (that’s about 15 seconds!), and the rest is basically all LLVM
optimization, LTO, and code generation. What’s interesting here that
didn’t quite show up as well before is there’s nearly 10% under
“exported symbols”, which looks like it involves a lot of
monomorphization stuff.
Dang, better tools make this way, way easier. But when
building my rendy hello-world program there’s an even
bigger gap of unaccounted-for stuff, almost 50%! So, there’s plainly
plenty of room for making the tools better. (It also makes clear that
monomorphization also happens as part of “codegen_crate”, and that
particular crate spends about 10% of its time on it; as I’d halfway
expected, instantiating giant piles of generics takes a lot of
work.)
What -Z self-profile doesn’t give us though, is memory
usage. Valgrind’s Massif tool seems perfect for what I want, but for
some reason it doesn’t seem to give any output at all when running with
rustc or cargo programs. There
are some docs that note that you may need to compile rustc with
jemalloc = false “for it to work well”, so maybe we should
try that. Massif does work with other Rust programs, so let’s try
building a rustc without jemalloc…? It looks like that’s the default on
Linux, but we should make sure anyway…
But now that I think of it, that won’t answer the question I started this whole thing to answer, which is… how gnarly is the LLVM IR that rustc produces? Or, more formally, how much LLVM IR gets fed into the start of LLVM’s optimizer, versus how much of it comes out the other end and gets turned into machine language? This actually just got mentioned recently in an update by one of the rustc optimization TOP MEN: “There’s been a long-running theory that the LLVM IR produced by the Rust compiler’s front end is low quality, that LLVM takes a long time to optimize it, and more front-end optimization could speed up LLVM’s code generation.” So, even the pro’s don’t know the answer for sure! We HAVE to at least try to find out.
To do this, we have to add a bit more instrumentation to rustc.
Digging ourselves deeper
So we have to build our own rustc. This is something I’ve done once
or twice, but I am far from comfortable with the workflow. However, as
usual, the
documentation is great. I love the official Rust teams so much. I’m
using the default config.toml config on the assumption that
this is a sane starting place. Looks like it is, so after a
git clone it’s just a matter of
./x.py build.
Building from scratch took 29 minutes on a Ryzen 1700. Whew! That
includes downloading some dependencies and doing a full bootstrap
though, which compiles the compiler at least twice, basically building
the new version of the compiler with the current one, and then
rebuilding the new compiler with itself to make sure it still actually
works. If we’re just hacking around for benchmarking we can omit that
second build. Again, the way to do this is in the docs:
./x.py build -i --stage 1 src/libstd, which gives us our
changed compiler and updated std in only 6 minutes. And
doing ./x.py check to only do typechecking takes less than
2 minutes from scratch, and a only a few seconds to check a small
change. Great.
I also tried building rustc on my Ryzen 2400G file server/HTPC, mostly out of morbid curiosity, but that machine only has 6 GB of memory available and so thrashed itself to death halfway through. Alas! It is worth noting that rustc plus the standard libraries and tools (rustdoc, rustfmt, etc) is about 1.3 million lines of Rust code. And LLVM adds another 8 million lines or so of C/C++, even if most of it is stuff not used directly in rustc such as tests, benchmarks… uh, and all of the clang compiler, apparently. I guess it’s just easier for rustc’s build system to download the whole LLVM package than to try to only pull the parts it actually needs.
…Hmm, for comparison, gcc 9.2.0 is somewhere in the 5-8 million line
range depending on how you measure, Go 1.13.3 is 2 million lines of Go,
and the Roslyn 3.2.0 C#+VB compiler is about 5-6 million lines. So yeah,
rustc is a bit of a chonker compared to most Rust programs, but
certainly isn’t unreasonable by the standards of professional-grade
compilers in 2019. It might still be quite valuable indeed to make a
small, portable Rust compiler someday, along the lines of
pcc or lcc, even if it only implements a
subset of the language. mrustc
is an alternative Rust compiler written in C++, but unfortunately it
doesn’t seem super active these days; it’s about 110,000 lines of code.
Naturally, lines of code is a terrible measurement so we’re not really
comparing apples to apples here, but it’s still interesting to see that
all these compilers fall into the same order of magnitude.
It’s actually pretty interesting to just read through the rustc book
because rustc is in the process of becoming more and more of an
incremental compiler, which drastically changes the structure.
Instead of the “pure function” of
source code -> object code I described at the start of
this, it’s turning into a “query based” architecture, which as the name
suggests, is a lot more database-y. I’m still grappling with the idea,
but it sounds like instead of a step-by-step computation pipeline it
turns the compilation process into a series of queries, where a query
can be something like “get me the type for this variable” or “get me the
compiled object code for this expression” or something, and each query
can either do work to compute this or just return memoized results that
have already been done elsewhere. This is naturally for the purpose of
not needing to recompile everything when a program changes,
just the bits that changed. It does seem like it would let the compiler
do things in a more out-of-order fashion, and queries that depend on
each other’s results will automatically sync waiting on results to be
produced and cached, so you don’t even have to express the dependencies
explicitly. Not a lot of compiler textbooks out there that build
compilers this way! But it seems a logical way to do things because an
incremental compiler doesn’t just do a pile of work and then is
finished, batch-style; it is more of an interactive program
where different parts of it may be fetching or altering data out of sync
with each other.
I am reminded of Lisp systems, and their Smalltalk cousins, which are very much on-the-fly, query-based compilers that keep code and metadata in an in-memory database. And Lisp systems traditionally excel at interactive usage, live modification, and fast turnaround. Coincidence? I think not.
Anyway, back to business! This query kind of system is foreign to me,
but the docs at least give me an idea of what’s going on. Alas, there’s
limits to the majesty of all mortals, including the rustc team, and so
the doc chapter for the codegen stuff is pretty empty. From here on it’s
up to us, and librustc_codegen_llvm seems like the place to
start, so let’s put on our hip waders and make an actual change to some
actual source code and see what happens…
impl CodegenBackend for LlvmCodegenBackend {
fn init(&self, sess: &Session) {
...
dbg!("FLARGLE!");
}
...That looks like a good first change to make, and fortunately it
compiles. Now how do we actually build stuff with our altered compiler?
Ah, you can tell rustup to define
a new toolchain. From your rustc source dir:
rustup toolchain link stage1 build/x86_64-unknown-linux-gnu/stage1/.
Then we go to nalgebra’s source dir and do
cargo +stage1 build, and while building
nalgebra it prints out some brand new and super
helpful debug statements. Perfect.
…man, starting to dig through the source code of a really
large open source program is so weird. It’s like wandering around a
giant cathedral that’s being constantly renovated and repaired and
maintained over the course of years by a giant team of invisible
crafters and architects, who mostly communicate via notes and designs
pinned to the walls in various places. (Sounds quite Mathic, really.) Did
you know that rustc has most of the groundwork laid for supporting other
backends besides LLVM? I didn’t, but it’s described very nicely by
someone named Denis Merigoux in a random README file. It looks like
src/librustc_codegen_ssa/ has an API for these backends to
implement and a bunch of backend-independent utility code, and
src/librustc_codegen_llvm/ actually implements this API for
the LLVM backend. There’s tons of knobs and stuff to fiddle, but the
bits I want to tinker with seem pretty simple. There’s a type
CodegenContext<T> that does the actual work, and then
you define your own T type for it (in this case,
LlvmCodegenBackend) and implement a few traits on it, and
you’re good to go. One of these traits provides useful-sounding methods
like codegen() and optimize(), and those sound
like exactly the methods we’re interested in. The only complexity then
comes from the fact that LLVM mutates everything in place and it’s
horrible.
Okay, there’s limits to how far I want to go into this right now, so
I’m going to just print out instruction counts for a LLVM
Module (compilation unit, hopefully a crate) before and
after LLVM is done optimizing it. What I REALLY want is to see the
initial LLVM IR generated from MIR to see how pessimal it looks, but
that sounds like the start of a whole new project. Let’s start simple.
There’s a Module::getInstructionCount() method in LLVM, but
there’s no FFI binding to call it from Rust, so heck, let’s just write
one. Some fairly simple additions to
rustllvm/RustWrapper.cpp and
librustc_codegen_llvm/llvm/ffi.rs and it builds, runs
without crashing, and produces output that seems at least vaguely
sensible. Annoyingly, due to the aforementioned query-based architecture
it’s hard to figure out what the exact sequencing and dependencies
between passes are. However, some poking around has me at least
pretty sure that optimize() and
codegen() are what we’re interested in and we can print
some instruction counts during them without anything else blowing up.
The only other likely-looking thing is some LTO-type stuff, and I’m
going to ignore it since LTO isn’t turned on by default and I’m not
super interested in it right now. So, optimize() and
codegen() look like promising places to start.
> cargo clean; cargo +stage1 rustc --release -- -C codegen-units=1
Compiling oorandom v11.1.0 (/home/icefox/src/oorandom)
Module oorandom.4cri1ig3-cgu.0, 654 instr's, before opt
Module oorandom.4cri1ig3-cgu.0, 272 instr's, after opt
Module oorandom.4cri1ig3-cgu.0, 272 instr's, before codegen
Module oorandom.4cri1ig3-cgu.0, 277 instr's, after codegen
Finished release [optimized] target(s) in 0.23sHoly cow, it works. And even outputs something vaguely plausible!
-C codegen-units=1 is there ’cause otherwise rustc
multithreads the build and breaks it into two parts, even for something
as small as oorandom, and each part has their own
instruction counts. The sums come out the same regardless of the number
of codegen-units though, so we’re probably doing
something right, but let’s just do codegen-units=1
to keep life simple. Let’s look at nalgebra:
Module nalgebra.buzfxn0q-cgu.0, 1336 instr's, before opt
Module nalgebra.buzfxn0q-cgu.0, 925 instr's, after opt
Module nalgebra.buzfxn0q-cgu.0, 925 instr's, before codegen
Module nalgebra.buzfxn0q-cgu.0, 923 instr's, after codegenThat’s not many actual instructions. Carrying on from the theme of
our earlier results, it looks like building nalgebra alone
doesn’t actually produce much code, it produces a bunch of
generics and type definitions and such that then need to be specialized
by being used somewhere before the compiler will actually do more with
them. So the 35 kLOC nalgebra produces less than 1000
actual LLVM instructions – if I’ve done these counts correctly.
Meanwhile, for the 14 kLOC ggez, the results look like
this:
Module ggez.b51tqrhr-cgu.0, 597,300 instr's, before opt
Module ggez.b51tqrhr-cgu.0, 198,942 instr's, after opt
Module ggez.b51tqrhr-cgu.0, 198,942 instr's, before codegen
Module ggez.b51tqrhr-cgu.0, 226,453 instr's, after codegenJust a bit beefier! And we see that on the more codegen-heavy
examples that LLVM’s optimization steps do cut the number of
LLVM instructions by 1/2 to 1/3, and then a bit more stuff gets added
during codegen, ~10% or so. Recall from our -Z self-profile
graphs that codegen is part of where monomorphization happens, so it is
logical that it could add more instructions. So for my
rendy thing that uses giant piles of complex generics, I’d
expect that step to add a lot of instructions:
Module ggraphics.9o1oe99j-cgu.0, 1,329,549 instr's, before opt
Module ggraphics.9o1oe99j-cgu.0, 267,528 instr's, after opt
Module ggraphics.9o1oe99j-cgu.0, 267,528 instr's, before codegen
Module ggraphics.9o1oe99j-cgu.0, 320,861 instr's, after codegenHmm, after-codegen is only 20% more instructions than before-codegen, while for ggez it was 13% more, so not as big a difference as I expected. Still goes in the direction we expected though, so there’s at least a BASIC sanity check! But dang, the post-optimization code size is 20% the pre-optimization code size! Number of instructions alone does not provide much information, since Eris only knows what what kind of code LLVM would find “easy” to optimize vs “hard”, let alone where rustc’s output falls on that spectrum. But making it cut the size of your program by a factor of 5 still seems like a good way to make your optimizer do a lot of work!
To continue this work from the angle of “what does the program look like before and after LLVM gets its paws on it”, my next thought would be to do statistics to instruction mixes or sizes of basic blocks or other stuff to try to figure out what’s going on. After all, if you have an intractably huge pile of complex data, you can just throw statistics at it for a while and hopefully get some clue of what it looks like. And I can’t think of many things that better fit the description of “intractably huge pile of complex data” than 1,329,549 LLVM instructions. However, that’s really the brute force kind of solution, and I would probably learn a lot more by actually taking the time to understand what’s going on instead of just describing its results. But that’s something for another time. Still, even this small bit has been pretty interesting.
It would be neat to see similar statistics statistics for clang compiling C or C++ as well, though. However, my experience has been that it is really quite difficult to compare Rust to C/C++ compilers, because it’s very difficult to find projects in both C/C++ and Rust that are close analogues of each other. Even when they do the same thing, they tend to do it in very different ways.
Encore!
Okay, I am hitting the edges of both my knowledge and patience, but there’s one last thing I want to try to do to close the loop. We’ve found and poked at the part of the compiler that goes from LLVM IR to actual machine code, looking at its optimization steps. Now I want to try things the other way around and find the code where we go from MIR to LLVM, and see what it looks like.
Aha, it’s in librustc_codegen_ssa. This is… hard to get
into, because I am not familiar with MIR and how it’s built, and so I
don’t know how the types in here fit together very well. There is a
BuilderMethods trait in that sub-library that appears to be
what you implement for a particular backend to turn MIR into that
backend’s IR though, and the librustc_codegen_llvm module
implements it. The implementation doesn’t look particularly complicated
or obscure actually, it just translates MIR basic blocks and math
instructions and whatnot into LLVM equivalents. It looks like MIR and
LLVM IR are not terribly different, which isn’t surprising in retrospect
since MIR was designed by people who’d been working a lot with LLVM
already. Nothing in that trait impl seems to do a lot of weird work or
turn single instructions into many, besides load_operand()
and write_operand_repeatedly() for some reason. So the LLVM
IR you get out seems like it should be pretty similar to the MIR you put
in. That’s both easier and less informative than I had hoped.
So, that’s as far as I feel like going with this. I guess it’s a short encore. Figuring out how MIR really works is out of scope, at least until I decide to write my own rustc backend. …Which I now know how to do. Hmmmm…
Conclusions
Well, that was an adventure! What have we learned? Not a GREAT deal of concrete stuff, I’m afraid, but a lot of general things:
- Production grade compilers are a lot more complicated than they look! …but good tools (and docs!) can make them comprehensible even to a non-expert.
- “Why is Rust slow to compile” is a very complicated question with a lot of possible answers, depending on your workload.
- A lot of work in compiling a Rust library gets pushed off until the library is actually used in an executable!
- Strong typing, borrow checking, monomorphization and all that jazz can take up a lot of time when used heavily…
- …but often you can also just blame LLVM and you won’t be very wrong.
From our (still sort of crude) benchmarks, one thing that consistently consumes a medium-ish chunk of time is MIR borrow checking, which makes me sad because if people somehow think that borrow checking is slow then other languages will be more hesitant to adopt it. But upon contemplation I’m not really worried about it ’cause MIR borrow checking is a very new feature, basically a better rewrite of the existing borrow checker to be more sound and convenient. Since it’s brand new, it probably hasn’t really been profiled and optimized much yet. I might not expect a 10x improvement in its performance, but 2-3x getting squeezed out of it next time someone takes a good hard look wouldn’t surprise me much. (Edit from the future: Apparently the compiler team has actually optimized it pretty heavily precisely because they didn’t want people to think the new borrow checker was slow, so the current implementation probably won’t see large improvements. Alas!)
As for our original thesis of “does rustc generate piles of mediocre
code and then just let LLVM clean it up?”, the tentative
conclusion appears to be “maybe yes”, just based on
before-and-after-optimization code sizes. And we’ve learned that to
really improve this situation, it has to be done at or before the level
of MIR, not in the MIR-to-LLVM or LLVM-optimization steps. But since
codegen is only one part of the picture, even if we make the fastest
compiler backend in the universe, nalgebra and similarly
metaprogramming-heavy crates will still take a lot of time to
typecheck.
There’s still a lot to learn about the codegen side, though, which is frankly what I’m more interested in. Does any other compiler really do better? What LLVM optimizations do the most work on reducing the big heap of input code? Which take the most time to perform? You’d have to know the answer to those to make a meaningful start at improving rustc’s MIR output to make things compiler faster. Then you get deeper into details such as, are there any patterns that rustc generates that LLVM particularly likes or dislikes? Since MIR and LLVM IR seem reasonably similar, is it really going to be faster to generate better MIR than to optimize LLVM IR? And can we take advantage of Rust’s properties to perform better optimizations than LLVM can do alone?
I’m not going to answer these questions, at least not any time soon! This was always intended to be a pretty light touch on the topic, I don’t have time and energy spending weeks digging into it, much as I’d like to. But like all good research, finding out some of the answers to this has raised more questions to think about.
To the next adventure!