ZfsNotes
Pragmatic notes on using ZFS on Linux. Written in June 2023, minor updates since then.
My use case: home terminal server and NAS running Debian Linux. Medium performance system in general, it’s a Ryzen 2400G with 16 GB of RAM. There’s 4 drives: 1 SSD with only the root system on it, 2 mirrored drives for data, and 1 separate drive that stores backups. The system drive is basically disposable and can be recreated from ansible automatically, and the backup drive has offsite backups behind it, so the only thing I care about using some kind of mirroring for is the data volume. It needs to have some RAID-ish thing, and it needs to be generally foolproof since managing the server is only occasionally fun.
Tech comparison
For having redundant drives on Linux with no specialized hardware, our choices are:
- Software RAID (Linux LVM or md)
- btrfs
- ZFS
The server has been running with the data drives on btrfs for years and it’s honestly fine. Years ago there were some nasty snapshot bugs that made me just stop using snapshots entirely, and I’ve never been interested enough to go back and play with them again. And a couple years after that a disk died and I vaguely recall having to reboot the system in recovery mode to actually get the system to run with the volume in degraded mode so I could unfuck it. Apart from that it’s been basically trouble-free. I’m just contemplating upgrading the drives and so want to use the opportunity to learn about ZFS.
Performance is basically a wash. All these solutions are similar-ish in perf, and all are worse than a single disk running XFS with no mirroring. ZFS has a slight reputation for less latency jitter, and some data backing it up, so that’s nice but for general purpose light usage not really enough to tip things much one way or another. As its reputation states, ZFS likes all the memory it can get, but is not particularly CPU-hungry. And the kernel seems to know that ZFS’s cache memory is cache, as far as I can tell, so will evict it as necessary.
I kinda dislike ZFS from a previous job that used it, which made it seem over-fiddly and resource-hungry. But I also kinda dislike btrfs for being flaky and slow, so let’s just try out ZFS for real and not let preconceptions contaminate me too much.
Concepts
ZFS manages multiple drives at once for you, yadda yadda, you know
this. Ok, terminology. “zpool” is a pool of multiple disks plus a
replication policy and a few global settings. (Edit: This is not quite
true but good enough for now, see the “Encore” section for details.)
Atop a zpool is zero or more “datasets”. A “dataset” is a generic term
for a filesystem, volume, snapshot, etc. The generic name format is
poolname/datasetname@snapshotname. A filesystem is, well, a
filesystem full of files, which is generally what I need to use ZFS for.
A volume is just a chunk of block storage, so you can create a volume
and then format it as ext4, or use it as backing storage for a VM or
database, or whatever. A snapshot is exactly what you think it is, a
read-only replica of the filesystem state at a given point in time. You
can mount snapshots in specific places to look at their contents and
such, which is nice. You can also clone and send a snapshot and stuff,
which is fancier than I need, though apparently a clone of a snapshot is
read-write so it be used to go back to a snapshot, tinker with it, and
then say “ok this is now our new filesystem”.
There’s also “vdev”’s. The goal of this guide is to not need to think about vdev’s.
Layout
There’s a plethora of ZFS guides full of interesting details and fiddly little performance hacks and tuning features for how to design your pool and volume layout. For something small like this, you don’t need them. From what Atma says, it comes down to:
- If you have 2 disks, use mirrored mode, the performance benefit over raidz1 is worth it.
- If you have 3-5 disks, use raidz1 (1-disk redundancy)
- If you have 5-10 disks, use raidz2 (2-disk redundancy) and start thinking about reading those fiddly little guides
- Above that, use raidz3 (3-disk redundancy) and definitely read those guides
- Deduplication uses up lots of RAM, so it’s probably only worth it if you’re using ZFS as a VM host or have lots of shared files and such on it. I’ll leave it off.
- Compression is much more of a no-brainer unless you’re really hard-up for CPU power, smaller on-disk data = faster I/O. LZ4 has a fairly meh compression ratio but is fastest and much better than nothing, zstd with default tuning options is fractionally slower but gets much better compression. So it’s probably worth using zstd, even though like 80% of my data by mass is music/videos/games that are already compressed. LZ4 also has the nice property of bailing out early if it realizes it’s trying to compress uncompressible stuff, though apparently this has been added to OpenZFS 2.2.
You can do lots of fancy things to set which disks are used for various internal logs and caches and stuff; I don’t need it. You can set SSD’s to be caches for underlying HDD’s; I don’t need it. You can do complicated multi-tier combinations of mirroring and raidz for max speed and resiliency across large disk arrays; I don’t need it. You might need it if you have high load databases or file servers, lots of video/streaming stuff, multiple VM guests, lots of giant compile jobs, etc. For basic everyday usage, you can generally just use the default settings and ride the SSD performance curve to victory.
The one low-level tweak that seems worth doing: The stupidly-named
and stupidly-fragile ashift parameter is the bitshift for
the minimum internal block/sector size for a disk. It has to be set when
a disk is added to a zpool, the setting for the entire zpool is the
lowest of all the disks in a zpool, and it is impossible to increase
without nuking the entire zpool and starting over. You set the parameter
by passing -o ashift=whatever when running
zpool create, and read it from an existing zpool with
zpool get ashift some_zpool. The default
ashift is 9 – so, 512 bytes per block. Most drives made
since 2011 or so have a physical block size of 4096 bytes, so can
benefit from an ashift of 12. In theory ZFS will ask the
disk what its block size is, but apparently many disks will lie and say
they use 512 byte blocks anyway, apparently to be compatible with
Windows XP. You can see what your disk claims by using
smartctl -a /dev/sdwhatever for SATA disks, or
nvme id-ns -H /dev/nvme0n1 (the “LBA Format” fields”; with
NVME you can actually set the sector size with nvme format,
though it will nuke all your data). Making the ashift
slightly larger than necessary generally doesn’t have bad effects
besides maybe wasting a little bit of disk space, while making it
smaller than necessary can thrash your performance by turning one big
write into lots of little writes. This may or may not matter for modern
SSD’s that aggressively cache and reorganize reads and writes under the
hood anyway, opinions seem to differ.
They should just make ashift default to 12 if the drive
reports a value smaller than that.
Actually doing stuff
Ok, first off, what the HELL zfs implementation to use? There appears
to be two available in Debian: zfs-dkms (kernel-space
driver) and zfs-fuse (userspace FUSE driver). The Debian
wiki describes the FUSE version as deprecated, so zfs-dkms
it is. Do apt install zfs-dkms zfsutils-linux.
Seems pretty straightforward. Create your storage pool:
zpool create <poolname> /dev/...for no mirroringzpool create <poolname> mirror /dev/... /dev...for mirrorzpool create <poolname> raidz /dev/... /dev...for RAIDZ1- You may want to consider using the identifiers under
/dev/disk/by-id/instead of sda/sdb etc.
Create your filesystem atop it:
zfs create -o mountpoint=/whatever <poolname>/<fsname>- Looks like the ZFS event daemon
zedwill mount it automatically for you? You can just dozfs set mountpoint=/whatever <poolname>/<fsname>and it will unmount from the old location and mount to the new location nicely. Neat. - You can nest filesystems. So if you have
mypool/whatevermounted on/whateveryou can dozfs create mypool/whatever/thingand it will be created and mounted by default at/whatever/thing.
Snapshots:
zfs snapshot <poolname>/<datasetname>@<snapshotname>– create snapshotzfs destroy <poolname>/<datasetname>@<snapshotname>– delete snapshotzfs list -t snapshot– list snapshotszfs rollback <poolname>/<datasetname>@<snapshotname>– switch to specific snapshot
Utility stuff:
zpool status– list pools, disks in them, errors, etc.zpool status -x– Just say “pools are healthy” if no errors, gives info if pool is degraded.zfs list– list pools and volumes, with space used and mount pointzpool list– list pools, with a bit of lower-level like fragmentation and dedup ratiozfs get all <name>– See properties for a pool/volume/snapshot. Properties for a pool are inherited automatically down to its volumes.zfs set compression=zstd <name>– Enable compression for a pool/volume and set it to zstd. Will it only compress new data? Not sure.zfs set dedup=on <name>– Set deduplication on, not necessary for me, uses lots of ram.zpool resilver <poolname>– restore a degraded zpool after you’ve replaced a bad disk in it. Resilver is still a really dumb name.zpool scrub <poolname>– Check checksums and fix data from them if necessary, it’s a bit of a lightweightresilver. Won’t fix a degraded pool but will find and fix some errors on disk.
Misc:
- There’s some settings for TRIM support for SSD’s, routine scrub jobs, etc. Debian gives you sane defaults and cron jobs for these.
- Most things are defined by “properties” set on a
pool/volume/snapshot. It appears that setting properties tends to take
effect immediately and be persistent, you don’t need to write them down
somewhere and then remount the volume. The man page for
zfs setappears to list all the properties and their valid values. - You can tell ZFS to export its volumes via NFS or CIFS, but it looks like it uses Samba or whatever anyway when you do and I have no idea how to configure it. I’ll just keep my existing Samba setup.
- For some weird reason, you can treat a zpool like a filesystem and
save files in it. And when you create a zpool named
fooit automatically creates the directory/fooand sets the zpool to mount there. You can set that zpool to have no mount point and nuke that dir with no ill effects, afaict. - Atma sez: “don’t be me. Don’t put files on the root of the ZFS hierarchy. Create a dataset and mount that instead for file storage. Because if you snapshot or back up the root dataset then you get everything. If you use a hierarchy of datasets you can flag some to snapshot and some not to and use automated snapshot tools on them.”
- ECC memory for ZFS is no more or less important than for any other filesystem. Do you need ECC memory? No. Do you want ECC memory? The answer is basically always “yes” no matter what filesystem you use. In ZFS the checksums can fix single-bit disk errors but be screwed over by single-bit memory errors, so ECC RAM basically makes the checksums more foolproof.
Don’ts
- Don’t use it as root filesystem on Linux (you can, it apparently takes a bit of work to get it to cooperate with GRUB but otherwise works fine, for me it probably isn’t worth the trouble)
- Don’t use it as swap (you can, it probably won’t work too well)
- Don’t fill it up past 80-85% (otherwise the CoW performance tanks; probably worth setting up a quota so that doesn’t happen)
Other stuffs
- How do I create a raidz zpool with say 3 disks, and add more disks to it later? Answer: add the new disks to the zpool as their own little raidz group, or destroy it and make a new one. Yeah, shit like this is what pisses me off about these systems. Growing storage systems incrementally is just something plebians do, amirite? Ok, it may be possible after all, apparently there was a patch for it submitted in 2021 but it may or may not have been merged
- However, what IS easy is expanding a zpool or volume to take advantage of larger disks, so that’s good at least. Like if you have a 3 TB and a 4 TB drive as a mirror, and you replace the 3 TB one with another 4 TB one, it’s easy to grow your filesystem to 4 TB.
- How do you set a quota for a zpool or volume?
zfs set quota=900M myzpool/myvolume, oh well that was easy. Again, can’t that just be the default? You can’t set it to a percentage though, RIP.
Practical results
After migrating my server to use ZFS:
- Works fine.
- But you sure as hell want to use the disk labels
from
/dev/disk/by-id/to specify the drives in your zpool instead of/dev/sdXor whatever. The docs warn that/dev/sdXcan get re-ordered, and Debian’s udev setup usually prevents that, but I guess ZFS tinkers with it somehow on its own accord because it absolutely re-ordered/dev/sdato be/dev/sdbsomehow and nearly gave me a heart attack thinking I’d formatted the wrong disk. - Removing and replacing a degraded drive is still touchy, I did it for practice and accidentally put the drive back into the zpool as a non-mirrored device so it ended up a striped device of two disks, which I then couldn’t fix without blowing away the zpool and starting over.
- The examples in the
zpoolandzfsman pages are pretty good for giving you the correct incantations for common tasks though, including removing/replacing degraded drives. - Since the
zedservice (or whatever) is responsible for mounting drives instead of/etc/fstab, having a non-ZFS drive mounted by/etc/fstabunder a ZFS directory will basically never work because those drives will get mounted before the ZFS drives do. Or maybe will work sometimes at random if the ZFS drive happens to get mounted first; idk! You can probably make systemd do it Right with enough work but fuck that. I just moved/home/bakto/bakand added a symlink for it. - Various docs in various places that use critically-unhelpful names
for their zpools like
zpoolortankare just the blurst. - It’s fast enough for spinny-rust drives that the filesystem prolly won’t be the bottleneck for anything I do.
- Someday I’ll care about playing with snapshots.
The settings I ended up using are:
> zfs get all | grep local
zhome quota 2.30T local
zhome mountpoint none local
zhome compression zstd local
zhome atime off local
zhome acltype posix local
zhome/homedata mountpoint /home localConclusions
I… think that’s all I really need, actually. Hmm. At least for basic usage. I still don’t heckin’ know what vdev’s are, but I don’t need to for only 2 disks. With this I’m pretty much ready to go.
ok, ZFS impressions:
- neat and actually very easy to use, the CLI tools are mostly very helpful
- snapshots!
- compression!
- I’m not doing VM’s or giant shared drives so there’s not much use for deduplication, which removes its most notorious memory-hog feature
- I’m not using a million disks so I don’t need to read most of the details about how to set up raid and the various tuning parameters for your particular disk layout
- I am in fact just using 2 disks and so can just use mirroring and forget about it
- ZFS is great for nerd sniping ’cause it can be infinitely deep
Resources
- The ZFS chapter of the FreeBSD Handbook is a good summary of anything else you might need
- This Ars Technica article from 2020 appears to have a decent introduction to all the fiddly little nuts-and-bolts I don’t want to think about.
- The Arch Linux wiki, of course, and there’s a tutorial that uses files on disk as your devices so you don’t need a pile of empty hard drives just for screwing around and experimenting.
- lobste.rs discussion has some interesting bits and pieces.
Encore: fine let’s think about vdev’s
I finally found some diagrams that make sense at https://ikrima.dev/dev-notes/homelab/zfs-for-dummies/, which is a useful reference written by and for people whose brain don’t work like mine. So let’s steal those diagrams and talk about them a bit.
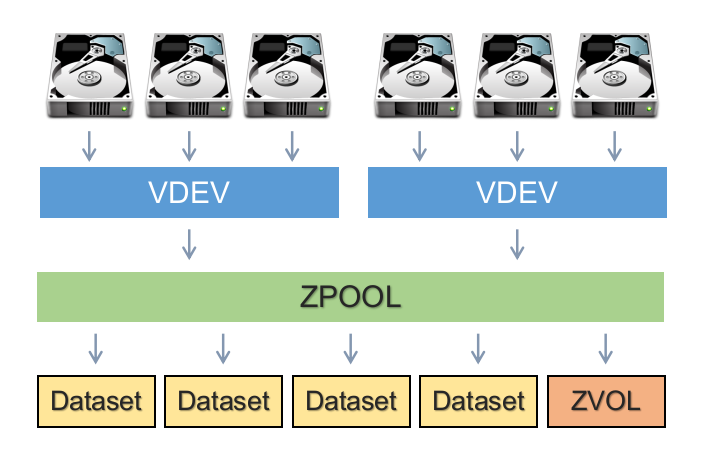
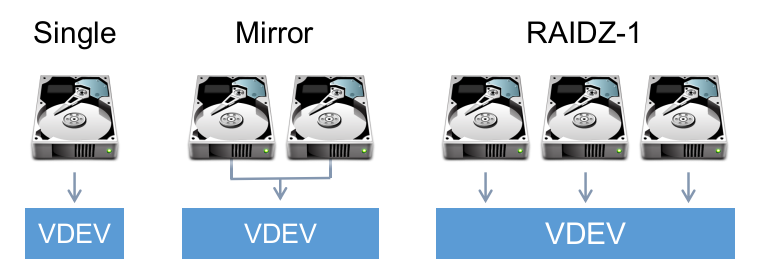
This finally makes it clear: a zpool is not your unit of replication, a vdev is. A vdev is a collection of disks and a replication policy (stripe, RAID1, etc):
Then a zpool is composed of one or more vdevs which, as far as I can tell(???) are always striped:
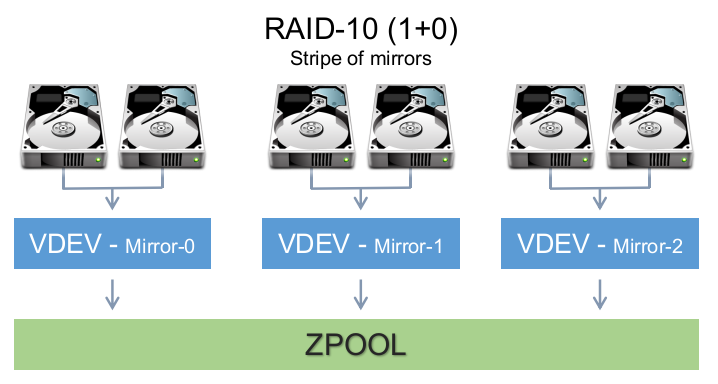
So this lets you take a big pile of disks and clump them together into multiple smallish, maybe-heterogenous fail-safe clumps, and then assemble arbitrary numbers of those clumps together into one big chonk. Another source says “never forget that a single vdev failing makes its whole pool fail”. So it sounds like this assessment is correct: a vdev is your unit of replication, and then a zpool is your unit of storage. This sounds like a weird distinction, but it might actually be pretty useful for scaling things up infinitely; it lets you choose the amount of redundancy you have at a granularity smaller than the entire storage pool. If you have 128 disks, then RAID6 alone might not protect you well enough, and will also tend to cap your read rate since no striping means you can really only read from one drive at a time. There’s some kinda interesting calculators out there to play with the details.
However, if you’re like me and will hopefully never need more than 4 drives in one zpool, the “pretend venv’s don’t exist” approach works fine.